6 Key Steps Of The Data Science Life Cycle Explained
The field of data science is rapidly growing and has become an essential tool for businesses and organizations to make data-driven decisions. The data science life cycle is a step-by-step process that helps data scientists to structure their work and ensure that their results are accurate and reliable. In this article, we will be discussing the 6 key steps of the data science life cycle and how they play a crucial role in the data science process.
Share this Post to earn Money ( Upto ₹100 per 1000 Views )
The field of data science is rapidly growing and has become an essential tool for businesses and organizations to make data-driven decisions. The data science life cycle is a step-by-step process that helps data scientists to structure their work and ensure that their results are accurate and reliable. In this article, we will be discussing the 6 key steps of the data science life cycle and how they play a crucial role in the data science process.
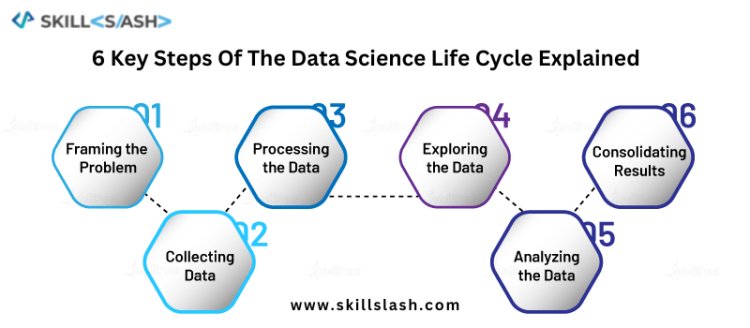
The data science life cycle is a cyclical process that starts with defining the problem or research question and ends with deploying the model in a production environment. The 6 key steps of the data science life cycle include problem definition, data collection and exploration, data cleaning and preprocessing, data analysis and modeling, evaluation, and deployment. Each step is crucial in the data science process and must be completed to produce accurate and effective models.
Problem Definition
When it comes to data science, the first and arguably most important step is defining the problem or research question. Without a clear understanding of what you are trying to achieve, it's impossible to move forward in the data science life cycle.
The problem definition step is where you determine the objectives of your project and what you hope to achieve through your analysis. This step is crucial because it lays the foundation for the rest of the project and guides the direction of the data collection, exploration, analysis, and modeling.
For example, if you're working in the retail industry, your problem might be to identify patterns in customer purchase behavior. This would then guide your data collection efforts to focus on customer demographics, purchase history, and other relevant data. On the other hand, if you're working in the healthcare industry, your problem might be predicting patient readmissions. This would then guide your data collection efforts to focus on patient health records, treatment history, and other relevant data.
It's important to note that the problem definition can change as the project progresses. As you explore and analyze the data, you may find that your original problem statement needs to be adjusted. This is normal and is a part of the iterative process of data science.
Data Collection and Exploration
Data collection and exploration are crucial steps in the data science life cycle. The goal of these steps is to gather and analyze the data that will be used to answer the research question or solve the problem defined in the first step.
There are several methods for data collection, including web scraping, APIs, and survey data. Web scraping involves using a program to automatically extract data from websites, while APIs (Application Programming Interfaces) allows for the retrieval of data from a specific source. Survey data is collected by conducting surveys or interviews with a sample of individuals.
Once the data is collected, it is important to explore it to identify patterns, outliers, and missing data. This can be done using tools such as R or Python, which allow for the visualization and manipulation of the data. During this step, it is also important to check for any potential issues with the data, such as missing or duplicate values.
Data exploration can be an iterative process, and it is important to keep the research question or problem in mind while exploring the data. This will help to ensure that the data being analyzed is relevant to the project and that any patterns or insights identified are useful for answering the research question or solving the problem.
Data Cleaning and Preprocessing
Data cleaning and preprocessing are crucial steps in the data science life cycle. These steps help to ensure that the data used in the analysis and modeling stages are accurate, complete, and ready for use. Data cleaning involves identifying and removing duplicates, missing data, and outliers. Data preprocessing involves preparing the data for analysis by converting it into a format that can be used by the chosen analysis and modeling tools.
One of the most important steps in data cleaning is identifying and removing duplicates. Duplicate data can lead to inaccuracies in the analysis and modeling stages, and can also increase the size of the dataset unnecessarily. This can be done by comparing unique identifiers such as ID numbers or email addresses.
Missing data is another issue that must be addressed during data cleaning. Missing data can occur for a variety of reasons such as survey participants not responding to certain questions or data not being recorded correctly. This can be addressed by either removing the missing data or imputing it with a suitable value.
Outliers are data points that lie outside the typical range of values. These points can have a significant impact on the results of the analysis and modeling stages, and therefore must be identified and dealt with accordingly. This can be done by using visualization tools such as box plots or scatter plots.
Data preprocessing involves converting the data into a format that can be used by the chosen analysis and modeling tools. This can include tasks such as converting categorical variables into numerical values, normalizing data, and dealing with missing data.
Data Analysis and Modeling
Data analysis and modeling is the fourth step in the data science life cycle. This step involves using various techniques to uncover insights and patterns in the data that were collected and preprocessed in the previous steps. The goal of data analysis is to understand the underlying structure of the data and extract meaningful information. The most common types of data analysis are descriptive, inferential, and predictive. Descriptive analysis is used to summarize the data, inferential analysis is used to make predictions based on the data, and predictive analysis is used to identify patterns and relationships in the data.
Modeling is the process of creating a mathematical representation of the data. The most common types of models used in data science are regression, classification, and clustering. Regression models are used to predict a continuous outcome, classification models are used to predict a categorical outcome, and clustering models are used to group data points into clusters.
Data analysis and modeling are important steps in the data science life cycle because they help to uncover insights and patterns in the data that can be used to make predictions and decisions. These insights and patterns can be used to improve business processes, make more informed decisions, and create new products and services.
Evaluation and Deployment
The final two steps in the data science life cycle are evaluating the model and deploying it. These steps are crucial in ensuring that the model is accurate and effective in solving the problem it was designed for.
First, the model's performance is evaluated using various metrics such as accuracy, precision, and recall. This helps to determine if the model is performing well and if any adjustments need to be made. For example, if a model is being used for a binary classification problem, it is important to check the precision and recall rates for both classes.
Once the model has been evaluated and any necessary adjustments have been made, it can be deployed to a production environment. This means that the model is now ready to be used by others to make predictions or decisions. The model can be deployed as an API, a web application, or integrated into an existing system.
It's important to note that the model should be regularly monitored and updated as needed. This is because the data and the problem it is solving may change over time, and the model may need to be retrained to reflect these changes.
Conclusion
The data science life cycle is a crucial process that helps to ensure accurate and effective models are produced. By following the six key steps of problem definition, data collection and exploration, data cleaning and preprocessing, data analysis and modeling, evaluation, and deployment, data scientists can ensure that their models are robust and can be deployed in a production environment.
At Skillslash, we understand the importance of mastering the data science life cycle, which is why our Data Science Course in Mysore is designed to give you the knowledge and skills you need to become a successful data scientist. Our program covers all of the key steps in the data science life cycle and is taught by industry experts who have years of experience in the field.
By enrolling in our program, you will learn the latest techniques and tools used in data science and gain hands-on experience through real-world projects. Our program will also provide you with the opportunity to network with other like-minded individuals and gain the confidence and skills you need to succeed in this exciting field.
Moreover, Skillslash also has in store, exclusive courses like Data Science Course In Pune, Data Science Course in patna and Data Science Course in Canada to ensure aspirants of each domain have a great learning journey and a secure future in these fields. To find out how you can make a career in the IT and tech field with Skillslash, contact the student support team to know more about the course and institute.






